코틀린 강의를 들으면서 한가지 기능에 대해 가장 쉽고, 빠르고, 코틀린만의 문법규칙을 사용하지 않고 작성하여 기능을 확인한 뒤 점진적으로 리팩토링 하며 코틀린 문법에 익숙해지려 한다.
강의를 들으면서 3단계에 걸쳐 동일한 기능을 리팩토링 하였고 그 과정을 기억해보려 한다.
[기능] 기능 설명
카테고리가 있는 책들의 현재 대출 현황에 대한 갯수를 보여준다.
{
"COMPUTER": 1,
"SCIENCE": 2,
"SOCIATY": 5
}카테고리 종류는 더 많지만 대출중인 유효 갯수가 있는 카테고리만 반환한다.
> bookRepository
현재 도서관이 보유중이 책 목록을 조회할 수 있다.
> BookStatResponse
카테고리별 대출중인 책의 갯수를 담는 DTO 이다.
[1] for loop 로 조회하기
- serivce
@Transactional(readOnly = true)
fun getBookStatistics_v1(): List<BookStatResponse> {
val results = mutableListOf<BookStatResponse>()
val books = bookRepository.findAll()
for (book in books) {
val targetDto = results.firstOrNull { dto -> book.type == dto.type }
if (targetDto == null) {
results.add(BookStatResponse(book.type, 1))
} else {
targetDto.plusOne()
}
}
return results
}
- BookStatResponse
data class BookStatResponse(
val type: BookType,
var count: Int,
) {
fun plusOne() {
count++
}
}
> 문제점
- 코드가 너무 길다
- BookStatResponse의 count가 가변 필드로 되어 의도치 않은 수정이 일어날 수 있다.
[2] ?. 와 ?: 사용하기
- service
@Transactional(readOnly = true)
fun getBookStatistics_v2(): List<BookStatResponse> {
val results = mutableListOf<BookStatResponse>()
val books = bookRepository.findAll()
for (book in books) {
results.firstOrNull { dto -> book.type == dto.type }?.plusOne()
?: results.add(BookStatResponse(book.type, 1))
}
return results
}
> 문제점
- call chain이 길어져 디버깅이 쉽지 않다.
- BookStatResponse의 count가 가변 필드로 되어 의도치 않은 수정이 일어날 수 있다.
[3] group by 사용하기
- service
@Transactional(readOnly = true)
fun getBookStatistics(): List<BookStatResponse> {
return bookRepository.findAll() //List<Book>
.groupBy{ book -> book.type } // Map<BookType, List<Book>>
.map { (type, books) -> BookStatResponse(type, books.size)} // List<BookStatResponse>
}
- BookStatResponse
data class BookStatResponse(
val type: BookType,
val count: Int,
)
> 코드 설명
1) findAll() 을 사용해 도서관에 등록되어 있는 모든 책을 조회한다 `List<Book>`
2) groupBy 를 사용해 카테고리 별 Map 으로 만들어준다 `Map<BookType, List<Book>>`
3) map 을 사용해 BookStatResponse DTO에 카테고리별 갯수를 담아준다 `List<BookStatResponse`
> 해결한 것
- BookStatResponse data class의 count 필드가 불변 필드로 되어 의도치 않은 수정을 막을 수 있다.
- 코드가 간결해 졌다.
> 문제점
도서관에 등록된 책의 전체 목록을 조회하여 그 갯수를 세는 과정이므로 db부하 등을 걱정해야 한다.
(전체 데이터 쿼리 => 메모리 로딩 + grouping)
[4] JPQL + Spring data JPA 활용하기 (예제 2개)
1] (위 예제와 이어지는 예제) 예제 1 : Book 기능
bookRepository에 커스텀 query function을 작성한다.
//jpql
@Query("select new com.group.libraryapp.dto.book.response.BookStatResponse(b.type, count(b.id)) " +
"from Book b group by b.type")
fun getStats(): List<BookStatResponse>
위 메소드를 사용하면 service에서는 매우 간결해진다.
@Transactional(readOnly = true)
fun getBookStatistics(): List<BookStatResponse> = bookRepository.getStats()
해당 쿼리를 통해 조회하면 h2 query 출력은 아래와 같이 나온다
select
book0_.type as col_0_0_,
count(book0_.id) as col_1_0_
from
books book0_
group by
book0_.type
> 해결한 것
groupBy 쿼리를 사용하여 db로부터 전체 데이터를 메모리에 로드하지 않고 필요한 정보만을 가져오게 되었다.
-> index를 사용해 튜닝 (성능 최적화) 할수있는 여지가 잇다.
> 문제점
- query 구문에서 외부 객체를 사용하기 위해서는 절대 경로를 전부 입력해 주어야 한다...
- 오타와 띄어쓰기를 매우 주의해야 한다..
2] 예제 2 : User 기능
유저와 대출히스토리 table이 각각 있는 db구조에서 유저와 해당 유저의 전체 대출 히스토리 기록을 한번에 조회하는 기능이 있다. 이때 대출기록이 없는 유저일지라도 유저목록으로는 반환되야 한다.
- service
@Transactional(readOnly = true)
fun getUserLoanHistories(): List<UserLoanHistoryResponse> {
return userRepository.findAllWithHistories().map(UserLoanHistoryResponse::of)
}
- repository
@Query("select distinct u from User u left join fetch u.userLoanHistories")
fun findAllWithHistories(): List<User>
> 문제점
- 오타 문제
- 조건이 추가된다면 또 다른 jpql 문을 작성해야 한다.
- 어떤것을 참조하는지 타고 들어가 봐야 안다.
[5] Querydsl (예제 2개)
0] 코프링에 querydsl 적용하기
1) gradle 추가
먼저 코프링 환경에서 querydsl을 사용하기 위해서 gradle 에 추가해주어야 한다.
// plugin
id "org.jetbrains.kotlin.kapt" version "1.6.21"
// dependecy
implementation("com.querydsl:querydsl-jpa:5.0.0")
kapt("com.querydsl:querydsl-apt:5.0.0:jpa")
kapt("org.springframework.boot:spring-boot-configuration-processor")참고로 환경은 스프링 부트 3버전 / intelliJ 23.1버전 / kotlin 1.16 버전 이다.
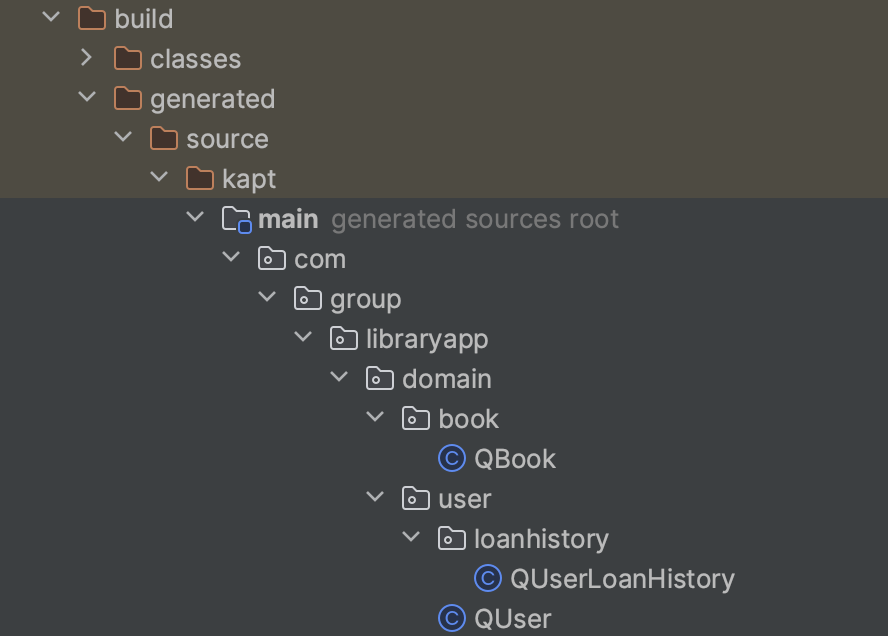
설정 변경후 빌드를 하면 `build > generated > source > kapt > main > .....{프로젝트 루트} ..... > domain` 에 User와 Book이 아닌 QUser QBook 처럼 앞에 Q가 붙은 클래스들이 생성된걸 볼 수 있다.
2) 스프링 빈 등록
그리고 나서 QuerydslConfig 파일을 만들어 Component로 등록하고 JPAQueryFactory를 Bean으로 생성한다.
import com.querydsl.jpa.impl.JPAQueryFactory
import org.springframework.context.annotation.Bean
import org.springframework.context.annotation.Configuration
import javax.persistence.EntityManager
@Configuration
class QuerydslConfig(
private val em: EntityManager
) {
@Bean
fun querydsl(): JPAQueryFactory {
return JPAQueryFactory(em)
}
}
다음으로 querydsl을 사용할 interface와 구현체 클래스를 작성한다. 이는 기존의 repository 는 jpql + jpa를 사용하기 때문에 분리하기 위함이다.
3) querydsl 인터페이스, 구현체 생성
- interface : UserRepositoryCustom
interface UserRepositoryCustom { ... }
- class : UserRepositoryCustomImpl
class UserRepositoryCustomImpl(
private val queryFactory: JPAQueryFactory
) : UserRepositoryCustom{ ... }
4) 기존 repository interface에 방금만든 것 상속
그리고 기존의 userRepository interface에서 Custom interface를 상속받도록 한다. 기존에 상속받고 있던 JPARepository는 그대로.
interface UserRepository : JpaRepository<User, Long>, UserRepositoryCustom{ ... }
1] 예제 2 : User 기능 => interface로 만들기
querydsl을 활용해 repository를 작성한다.
- UserRepositoryCustom
interface UserRepositoryCustom {
fun findWithHistories(): List<User>
}
- UserRepositoryCustomImpl
import com.group.libraryapp.domain.user.QUser.user
import com.group.libraryapp.domain.user.loanhistory.QUserLoanHistory.userLoanHistory
import com.querydsl.jpa.impl.JPAQueryFactory
class UserRepositoryCustomImpl(
private val queryFactory: JPAQueryFactory
) : UserRepositoryCustom{
override fun findWithHistories(): List<User> {
// querydsl 로 작성
return queryFactory.select(user).distinct()
.from(user)
.leftJoin(userLoanHistory).on(userLoanHistory.user.id.eq(user.id)).fetchJoin()
.fetch()
}
}
의존성 주입을 위해 생성자에 JPAQueryFactory를 적어주어야 한다. query 구문에서는 기존 Entity class가 아닌 Q클래스를 사용한다.
2] (위 예제와 이어지는 예제) 예제 1 : Book 기능 => class로 만들기
BookQuerydslRepository 라는 클래스를 정의한다.
@Component
class BookQuerydslRepository(
private val queryFactory: JPAQueryFactory,
) {
fun getStats(): List<BookStatResponse> {
return queryFactory.select(Projections.constructor(
BookStatResponse::class.java,
book.type,
book.id.count()
))
.from(book)
.groupBy(book.type)
.fetch()
}
}> Projections.constructor
주어진 DTO의 생성자를 호출한다. (첫번째로 나오는 클래스의 생성자)
그 뒤 인자들은 생성을 위한 초기값으로 사용된다.
select type, count(book.id) from book;
위 쿼리문을 해석하면 아래와 같다.
select type, count(book.id)
from book
group by type;
'DEV-ing log > Java & Kotlin' 카테고리의 다른 글
| [IntelliJ & Kotlin] 빌드 시 Downloading kotlinc-dist? 무한 로딩 오류 (0) | 2024.04.30 |
|---|---|
| [Kotlin] 코틀린의 장점 : Null Safe (0) | 2024.04.29 |
| [Java] 기본 문법 이해하기 (0) | 2024.04.26 |